







智谱 AI 再放 “大招”,30 秒将任意文字生成视频
继文本生成、图像生成后,视频生成也加入到了 “内卷” 行列。
7 月 26 日的智谱 Open Day 上,在大模型赛道上动作频频的智谱 AI,正式推出视频生成模型 CogVideoX,并放出了两个 “大招”:
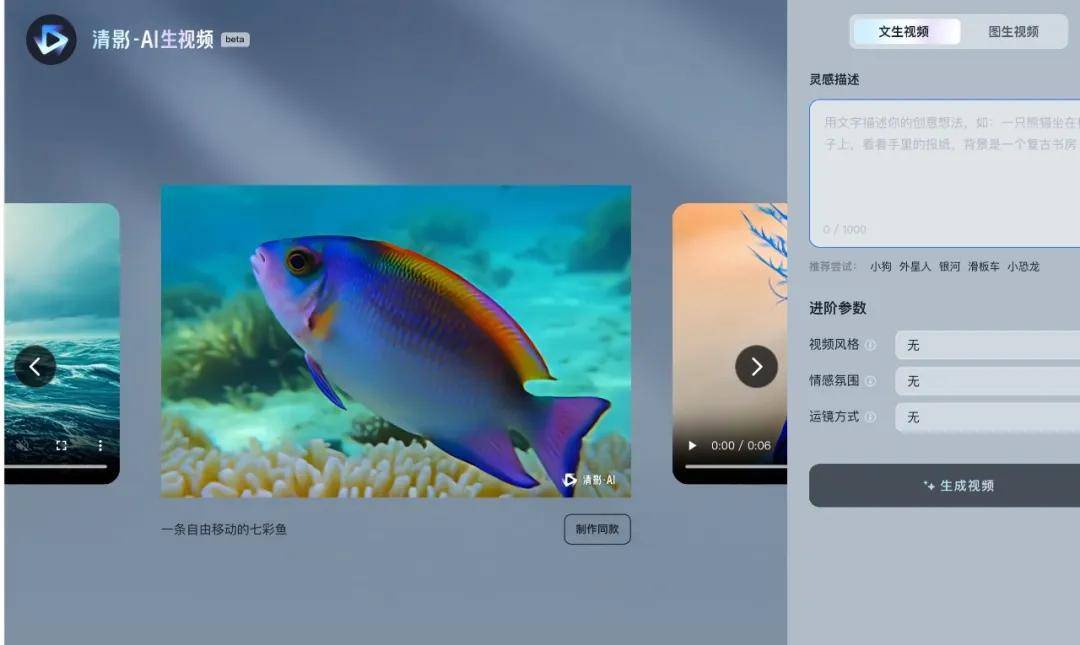
一个是智谱清言打造的视频创作智能体清影,可使用文本或图片生成时长 6 秒、1440x960 清晰度的高精视频。
另一个是智谱清言小程序上线的 “让照片动起来”,可以直接在小程序中上传照片,输入提示词生成动态视频。
不同于一些小范围开放或预约才能使用的产品, 清影智能体面向所有用户开放,输入一段提示词,选择自己想要的风格,包括卡通 3D、黑白、油画、电影感等等,配上清影自带的音乐,就能生成充满想象力的短视频。企业和开发者也可以通过调用 API 的方式,体验文生视频和图生视频能力。
由此引出了这样一个问题:目前视频生成类产品仍处于 “可玩” 的阶段,距离商用仍然有不小的鸿沟,智谱 AI 的进场将产生什么样的影响?
01 更快更可控的 “清影”
在 Sora 引爆视频生成赛道后,行业内掀起了一场连锁反应,先是 Runway、Pika 等产品在海外市场走红,国内在 4 月份以后也陆续曝光了多个文生视频类大模型,几乎每个月都会有新产品上线。
市场层面越来越热闹,体验上却陷入了相似的困局,确切的说是两大绕不过去共性问题:
一是推理速度慢,哪怕只是 4 秒的视频,也需要 10 分钟左右才能生成,而且视频越长,生成的速度越慢;
二是可控性差,在限定的语句和限定的训练样本内,可以有不错的效果,一旦 “越界” 就会出现 “群魔乱舞” 的情况。
有人将其比作为游戏中的 “抽卡”,多试几次才会生成想要的效果。然而一个无法掩盖的事实是,倘若文生视频要尝试 25 次才能生成一次可用的,每次生成的时间动辄 10 分钟,意味着想要获得一条几秒中的视频,需要长达四个多小时的时间成本,所谓的 “生产力” 也就无从谈起。
在智谱清言里试用了 “清影” 的文生视频和图生视频功能后,我们发现了两个令人惊艳的体验:生成一条 6 秒的视频,只需要花费 30 秒左右,推理时间从分钟级被压缩到了秒级;采用 “镜头语言 + 建立场景 + 细节描述” 的提示词公式,一般 “抽两三次卡” 就能够获得让人满意的视频内容。
以文生视频的场景为例,给 “清影” 输入 “写实描绘,近距离,猎豹卧在地上,身体微微起伏” 的指令后,一分钟内就生成了一段 “以假乱真” 的视频:风吹动草地的背景,猎豹不断晃动的耳朵,随着呼吸起伏的身体,甚至每一根胡须都栩栩如生……几乎可以被误认为是近距离拍摄的视频。
为什么智谱 AI 可以 “跳过” 行业内普遍存在的痛点?因为所有的技术问题,都可以通过技术上的创新解决。
隐藏在智谱清言视频创作智能体 “清影” 背后的,是智谱大模型团队自研打造的视频生成大模型 CogVideoX,采用了和 Sora 一样的 DiT 结构,可以将文本、时间和空间融合。
通过更好的优化技术,CogVideoX 的推理速度较前代模型提升了 6 倍;为了提升可控性,智谱 AI 自研了一个端到端视频理解模型,为海量的视频数据生成详细的、贴合内容的描述,以增强模型的文本理解和指令遵循能力,使得生成的视频更符合用户的输入,并能够理解超长复杂 prompt 指令。
如果说市面上的同类产品还在 “可用” 上下功夫,创新上 “全垒打” 的智谱 AI 已经进入了 “好用” 的阶段。
直接的例子就是智谱清言同步提供的配乐功能,可以为生成的视频配上音乐,用户需要做的仅仅是发布。无论是没有视频制作基础的小白用户,还是专业的内容创作者,都可以借助 “清影” 让想象力化为生产力。
02 Scaling Law 再次被验证
每一次看似不寻常的背后,都有其必然性。在同类产品要么不开放使用,要么还处于阿尔法版本的阶段,“清影” 之所以成为人人可用的 AI 视频应用,离不开智谱 AI 在频生成大模型上的多年深耕。
时间回到 2021 年初,距离 ChatGPT 的走红还有近两年时间,诸如 Transformer、GPT 等名词只是在学术圈讨论时,智谱 AI 就推出了文生图模型 CogView,可以将中文文字生成图像,在 MS COCO 的评估测试中超过 OpenAI 的 Dall·E,并在 2022 年推出了 CogView2,解决了生成速度慢、清晰度低等问题。
到了 2022 年,智谱 AI 在 CogView2 的基础上研发了视频生成模型 CogVideo,可以输入文本生成逼真的视频内容。
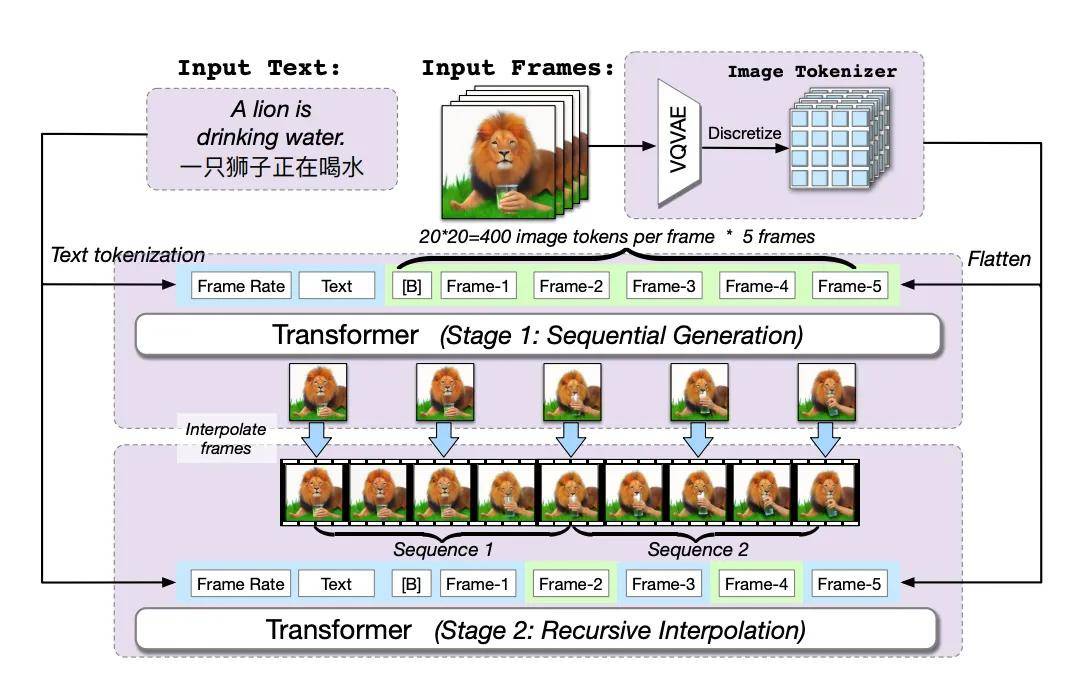
彼时外界还沉浸在对话式 AI 的场景中,视频生成并不是焦点话题,但在前沿的技术圈里,CogVideo 已经是炙手可热的 “明星”。
比如 CogVideo 采用的多帧率分层训练策略,提出了一种基于递归插值的方法,即逐步生成与每个子描述相对应的视频片段,并将这些视频片段逐层插值得到最终的视频片段,赋予了 CogVideo 控制生成过程中变化强度的能力,有助于更好地对齐文本和视频语义,实现了从文本到视频的高效转换。
Meta 推出的 Make-A-Video、谷歌推出的 Phenaki 和 MAGVIT、微软的女娲 DragNUWA 以及英伟达 Video LDMs 等等,不少视频生成模型都引用了 CogVideo 的策略,并在 GitHub 上引起了广泛关注。
而在全新升级的 CogVideoX 上,诸如此类的创新还有很多。比如在内容连贯性方面,智谱 AI 自研了高效三维变分自编码器结构(3D VAE),将原视频空间压缩至 2% 大小,配合 3D RoPE 位置编码模块,更有利于在时间维度上捕捉帧间关系,建立起视频中的长程依赖。
也就是说,视频创作智能体 “清影” 的出现绝非偶然和奇迹,而是智谱 AI 日拱一卒式创新的必然结果。
大模型行业有一个著名的定律叫 Scaling Law,即在不受其他因素制约时,模型的性能和计算量、模型参数量、数据大小呈现幂律关系,增加计算量、模型参数量或数据大小都可能会提升模型的性能。
按照智谱 AI 官方给出的信息,CogVideoX 的训练依托亦庄高性能算力集群,而且合作伙伴华策影视参与了模型共建、另一家合作伙伴 bilibili 参与了清影的技术研发过程。沿循这样的逻辑,“清影” 在生成速度、可控性上超预期的体验,无疑再一次印证了 Scaling Law 定律的有效性。
甚至可以预见,在 Scaling Law 的作用下,后续版本的 CogVideoX,将拥有更高分辨率、更长时长的视频生成能力。
03 “多模态是 AGI 的起点”
一个可能被习惯性忽略的信息在于,智谱 AI 并没有将 “清影” 作为独立的产品,而是以智谱清言的智能体上线。
个中原因可以追溯到智谱 AI CEO 张鹏在 ChatGLM 大模型发布会上的演讲:“2024 年一定是 AGI 元年,而多模态是 AGI 的一个起点。如果想要走到 AGI 这条路上去,只停留在语言的层面不够,要以高度抽象的认知能力为核心,把视觉、听觉等系列模态的认知能力融合起来,才是真正的 AGI。”
5 月份的 ICLR 2024 上,智谱大模型团队在主旨演讲环节再次阐述了对 AGI 技术趋势的判断:“文本是构建大模型的关键基础,下一步则应该把文本、图像、视频、音频等多种模态混合在一起训练,构建真正原生的多模态模型。”
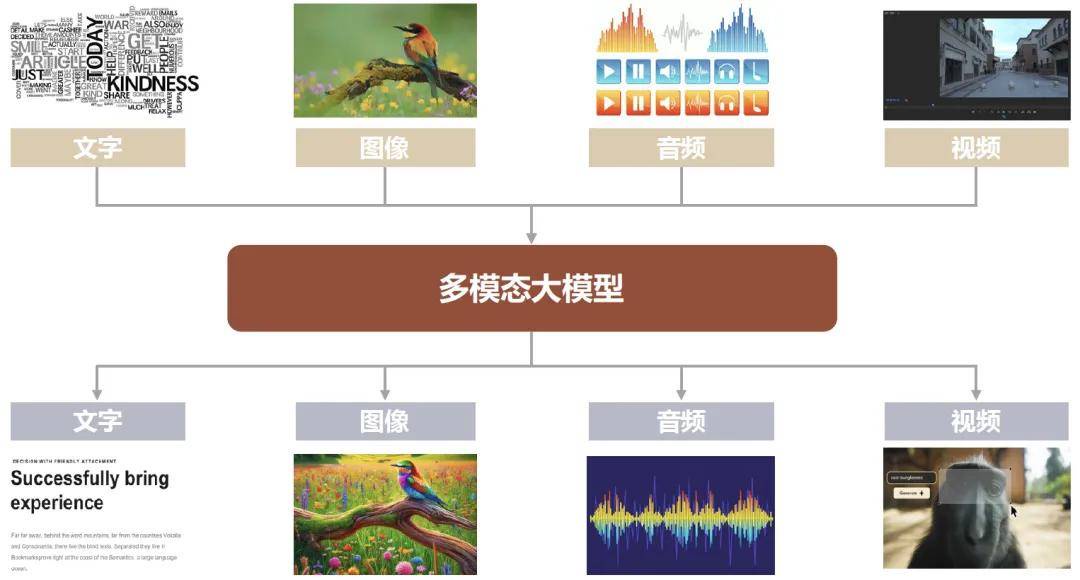
过去一年多时间里,大模型的热度一浪高过一浪,却未能摆脱 “缸中大脑” 的局限,应用场景十分有限。而大模型想要脱虚向实,想要走进实际的生活和工作中创造价值,必须要长出手脚的执行能力,比如在语言能力外延伸出听觉和视觉的能力,并通过这些能力和物理世界进行无缝连接。
再来审视视频生成大模型 CogVideoX 和视频创作智能体 “清影”,无疑可以得出一些不一样的答案。
CogVideoX 的文生视频、图生视频能力,可以看作是对认知能力的拆解,先实现单项能力的突破;以视频创作智能体形态出现的 “清影”,可以看作是对不同模型能力的收拢,在原生多模态大模型还不太成熟的情况下,用户可以通过多个智能体的组合,高效且精准地解决现实问题。
可以佐证的是,在智谱 AI 的大模型矩阵里,已经涵盖具备视觉和智能体能力的 GLM-4/4V、推理极速且高性价比的 GLM-4-Air、基于文本描述创作图像的 CogView-3、超拟人角色定制模型 CharacterGLM、擅长中文的向量模型 Embedding-2、代码模型 CodeGeeX、开源模型 GLM-4-9B 以及视频生成大模型 CogVideoX,客户可以根据不同的需求调用不同大模型,找到最优解。
而在 To C 应用方面,目前智谱清言上已经有 30 多万个智能体,包括思维导图、文档助手、日程安排等出色的生产力工具。同时智谱 AI 还推出了由数十万个 AI 体组成的多智能体协作系统——清言 Flow,不仅限于单一智能体的交互,涉及多轮、多态、多元的对话交互模式,人们仅需通过简洁的自然语言指令,就能处理高度复杂的任务。
做一个总结的话:现阶段距离真正意义上的 AGI 还有不小的距离,但智谱 AI 正在用 “单项突破,能力聚合” 的方式,提前让 AGI 照进现实,让强大的大模型能力真正用来帮助人们的工作、学习和生活。
04 写在最后
需要正视的是,目前视频生成大模型对物理世界规律的理解、高分辨率、镜头动作连贯性以及时长等,仍存在非常大的提升空间。
在通往 AGI 的路上,智谱 AI 等大模型厂商不应该是孤独的行路者。作为普通用户的我们,也可以是其中的一员,至少可以在智谱清言上用自己的 “脑洞” 生成有趣的视频,让更多人看到大模型的价值,利用 AI 提升创作效率的同时,加速多模态大模型不断走向成熟。