
训练人工智能的中国县城工人

全世界都在谈论 ChatGPT 将带来颠覆性的技术革命,但人工智能训练师李杰却一点也激动不起来。为了完成单价 4 分钱的计件工作,李杰和几十个人坐在一间摆设如同初代网吧的屋子里,每天对着电脑划拉鼠标几千次。他的职责是为训练人工智能模型准备 “饲料”,将大量的文字、语音、图像打上标记——“眼珠”、“四川话”、“绿化带”。
蓝字计划

作者 | 林石
插画 |AI 绘图工具 Disco Diffusion
原创首发 | 蓝字计划
全文字数 | 约 4300
全世界都在谈论 ChatGPT 将带来颠覆性的技术革命,但人工智能训练师李杰却一点也激动不起来。
为了完成单价 4 分钱的计件工作,李杰和几十个人坐在一间摆设如同初代网吧的屋子里,每天对着电脑划拉鼠标几千次。
他的职责是为训练人工智能模型准备 “饲料”,将大量的文字、语音、图像打上标记——“眼珠”、“四川话”、“绿化带”。只有被标注过的数据,才能被人工智能模型识别,训练出它的分辨能力。
李杰做得最多的是道路图片标注,亦即给道路图片上的物体标注好名称、颜色等详细信息,业内俗称 “拉框”。
效率高的时候,他一天可以拉 2000-3000 个框,按照一个框 4 分钱计算,他一个月能赚三千块左右。对于职校毕业、身在西北县城的青年来说,这份收入还过得去。

| 一家数据标注工厂
同样的场景也出现在非洲的肯尼亚。该国首都内罗毕有 30 多名工人,成为了 ChatGPT 的数据标注员,他们每天工作 9 个小时,阅读 150-200 段文字,并标注出其中包含性、暴力与仇恨言论的内容。由于每天阅读大量极具冲击力的文字,有人会因为一段描写而做上一周噩梦。
这些工人能获得每小时 1.32 美元的税后收入,如果完成既定的任务,时薪可以上升至 1.44 美元,并有大约 70 美元的奖金,相当于一个月挣 2500 元—3000 元人民币,比当地一般蓝领工作强些。
在人工智能产品卷起巨浪的时候,从肯尼亚、乌干达再到印度、中国,水下还有一群不被看见的 “人工智能训练师”,在简陋的工作环境下,以最简单的技能,与最前沿的技术产生了联系。

伺候人工智能
李杰对人工智能的理解,是手机上的智能语音助手,“就好像苹果的 Siri”。
他在职校念电子商务,同学大多去了电商公司当客服,他时常听到同学对工作的抱怨。相较之下,数据标注的工作枯燥,却也纯粹,他只需要按部就班地完成任务、“可以在办公室吹空调,也没什么难度,就是有点费眼睛”。

| 给汽车进行 “拉框”,一张图片就要重复数次类似操作
在 2021 年版的《人工智能训练师国家职业技能标准》中,对该职业的能力特征描述是 “具有一定的学习能力、表达能力、计算能力;空间感、色觉正常”,普遍受教育程度写的是 “初中毕业”。言外之意,这是一份几乎零门槛的职业。
年过 50 岁的郭梅,原本在山西当地的煤矿上班,“抬头是山,低头是煤”。离开煤矿之后,她长时间找不到工作,最后成为数据标注基地中的一名员工,每天要拉两千个以上的框。“我从来没有想过自己会和无人驾驶、人工智能有关系。”

| 正在给汽车拉框的数据标注员
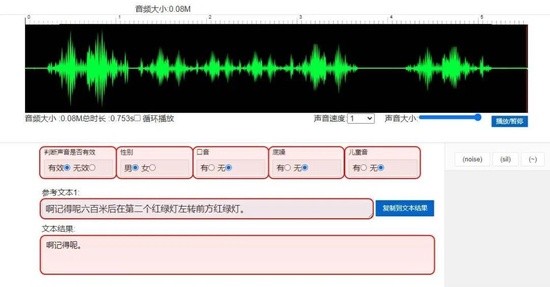
除了 “拉框”,李杰也会接到语音标注的项目,通常是甲方采集到的不同地域、不同人群的语音,李杰必须戴上耳麦,仔细地辨认出每一个声音的含义。
一天下来,他要听来自几百个陌生人在不同场景下的发言,可能是伴随着车流声、喇叭声的中年男人在马路上大声质问,可能是讲着广东普通话的阿姨对着麦克风发出指令,有时候,他甚至会听到脏话。
这些声音被李杰一一转录成准确的文字,有时还需要打上说话人的性别、情绪等更细分的标签,最后教会人工智能模型理解人类的语言,用于智能客服、智能音箱、地图导航等产品中。
人工智能的三大基石是数据、算力与算法,数量越多质量越高的数据,往往越能够训练出更 “聪明” 的模型。
人工智能的主流方向是深度学习。在过去,由人来告诉机器,猫身上都有哪些特征,机器根据这些特征判断一个物体是不是猫;深度学习则是通过 “喂养” 大量不同猫的图片,机器就能自行归纳出猫的特征。这就需要大量经人工标注的图片,俗话说,有多少智能,就得付出多少人工。
数据标注领域有过一个神话——ImageNet 项目。这个项目数据库拥有超过 1400 万张已被标注的图片,其中识别出的物体种类超过 20000 种——包括 120 个不同品种的狗。

| ImageNet 图片集中有 1400 多万张标注图片,其中超 100 万张带有边框
项目源于斯坦福大学的人工智能专家李飞飞。2009 年,业内普遍研究方向都是模型与算法,她另寻蹊径,改进数据质量。如今,ImageNet 已经是世界上最大的图像识别数据库,被用于成千上万个人工智能研究项目和实验。
而在 ImageNet 项目背后,是来自 167 个国家的 5 万名数据标注员,他们足足花了三年时间才完成了全部图片的标注。
李杰算是图片标注的老手了,通常发给他的数据包内通常会有数百张不等的道路拍摄照片,李杰需要按照项目方的要求,对道路上的车辆、行人、绿化带等物体标注。另外还有一种常见的标注任务,则是标注道路的车道线。
这种数据标注要求特别多,“框框不能超过也不能小于,更不能漏点,一出错误验收不合格就得重新拉”。这些数据的最大流向是用于自动驾驶的机器学习,要确保驾驶安全,通常需要提供数以百万计的标注数据对人工智能加以训练——背后则是无数在电脑前点击鼠标、敲击键盘的李杰们。
互联网版富士康
贵阳,大数据之城。
在距离贵阳市中心约 50 公里的惠水县百鸟河数字小镇,有一家拥有超过 500 名数据标注员的公司梦动科技——其中的一半人,是附近盛华职业学院的学生。
大三学生郑成安在梦动科技实习,公司里的全职员工只有十来个人,管理层也是学校里的老师,“上课就是上班,老师就是经理”。

| 位于百鸟河数字小镇的盛华职业学院
他很热爱这份工作,数据标注给了他生活多一种选择。他在上高职之前甚至没碰过电脑,现在却可以凭借一份电脑前的兼职,一个月能拿到 1500 元以上的收入。
郑成安所在的惠水县,在贵阳 88 个县区中经济水平排在中游,2020 年时的 GDP 为 139.16 亿元,农村常住居民人均可支配收入 12924 元——相当于每月 1000 元出头。
有时候为了多挣一些生活费,碰上紧急的项目,郑成安会主动加班。他清楚地知道,标注员的工作很难一直做下去,他暗自下定目标,要成为管理标注员的人。
像贵阳这样的城市,中国不止一个。
数据标注产业的诞生最早可以追溯到 2005 年。当时,著名计算机视觉专家、人工智能专家朱纯松从美国回到了故乡湖北鄂州,创办了莲花山研究院,筹建据称是当时世界上最早的大数据标注团队。
在深度学习成为人工智能主流之后,日益增长的互联网大数据成为了人工智能的最好养分。
据数据公司 IDC 统计,全球每年生产的数据量将从 2016 年的 16.1ZB 猛增至 2025 年的 163ZB,其中 80%-90% 都是原始数据数据。这些在经过清洗和标注后,变成标准化格式数据,才能被人工智能所理解。
作为劳动密集型产业,数据标注企业更多地选在三四线城市落地,地方政府无论是为了扶贫或是搭上互联网的顺风车,都能与互联网公司们一拍即合。
2018 年,位于太原的山西转型综合改革示范区就与百度达成合作,打造了号称 “全国范围内人员和产值规模最大的单体数据标注基地”,基地占地面积超 1 万平米,已经引进了至少 35 家数据标注公司,超过 2000 名数据标注员。

| 百度山西数据标注基地
在新疆和田,有 4000 人在当地的数字经济产业园从事数据标注工作,和田地区更是抛出了 “数据标注产业之都” 和 10 万人数据标注就业基地的目标。
在河南,数百家数据标注公司从无到有;在济南,山东第一个数据标注基地,已经容纳了 1500 名 “人工智能训练师”;在新三板上市的数据堂,也在保定、合肥,分别建立了容纳数百名数据标注员同时工作的基地。
而数据标注员身上的标签是 “互联网民工”、“赛博流水线”。而对于绝大多数身在其中的人而言,一个互联网版的富士康,已经是当下不可多得的选择。
“教会徒弟,饿死师傅”
当数据标注成为 “风口”,淘金者也随之而来。
2017 年,周华偶然在朋友口中得知,做数据标注能赚钱,刚刚创业失败的他,决定再赌一把。
他算过一笔账,一名数据标注员一个月的产值能到 7000 元,除掉 3000 元的工资和质检、场地设备等费用,还能赚 1500 元。“如果招 100 个人,一个月就赚 15 万元。”
他找来合作伙伴,采购电脑、确定场地,又迅速地招聘了一批没有学历、工作经验要求的数据标注员,紧锣密鼓地接单。

| 正在工作的数据标注员
此时的数据标注产业,赶上人工智能创业潮。根据前瞻产业研究院统计,数据标注公司从 2014 年开始不断增加,并在 2017 年达到高峰,当年数据标注相关融资事件达到 9 起,到 2021 年 4 月,已经有有 18 家公司获得融资,投融资事件 39 起。
数据标注行业有三种不同的公司,一种是大型互联网公司内部的数据标注部门,处理公司内部的数据;一种是像数据堂这类有自己基地的数据标注公司,他们有独立承接订单的能力,甚至外包给第三方;数量最多的则是以工作室形态存在的小公司,他们通常只能在众包平台上接单,或者第三方中介公司转过来的层层分包的订单——在平台上,他们或被称为 “公会”、“团队”。
周华的工作室便属于最后一种,当时主要依赖百度众测的平台订单,平台上会分发各类任务,在行业内称为 “放题”,包括数据采集、图片标注、文本标注等。据百度众测的数据,平台上有 2500 万的注册用户。
但百度众测上的单并不是都能到周华的手里。有时候他必须主动承接一些二手乃至三手的订单,那些掌握渠道的公司则可以赚取差价。
同样和他一样撞上风口的,还有当时还是创业公司的星尘数据。
星尘数据的创始人章磊,在华尔街、硅谷工作 10 年,曾在投资平台 CircleUp 担任资深数据科学家。2017 年回国时,他本想继续在投资领域创业,尝试打造一个投研机器人——通过对大量公司年报、招股书等金融文档的学习,辅助投资人决策。当时国内的数据标注往往往往只能机械化地完成客户需求,这种 “新颖” 的数据标注要求,业内难以实现。章磊却看到了机会。
他创办的星尘数据,号称为客户量身打造数据标注方案。这家位于北京三里屯的公司,早在 2018 年 1 月就完成 1000 万元人民币的 Pre-A 轮融资,最新在去年 8 月又完成了 5000 万人民币的 A 轮融资,如今更多是做 “数据标注平台” 的生意——他们会去竞标大公司给出的数据标注订单,再分包给类似一些小型的 “数据工厂 “,周华是他们的其中一个合作伙伴。
2005 年成立的海天瑞声,在此次生成式人工智能风潮中更是 “赚麻了”。这家在业内以语音数据标注著称的公司,21 年在科创板成功上市,今年一月以来,股价从每股 60 元左右暴涨到了每股超过 200 元。
| 海天瑞声最早从语音标注项目起家
毕竟对于国内众多研发人工智能的大厂而言,基础的数据标注是刚需,却不可能永远自己来做。那么只要有订单,无论是周华这样的工作室,还是海天瑞声、星尘数据这样的大公司,都能赚个盆满钵满。并非所有入局者都能有周华的运气,周华就知道不少同行,因为订单缺乏、结算周期长,公司早早退场。
当然,随着 GPT-4 和文心一言的陆续出场,人工智能正 “升级换代”,数据标注行业也伴随着新的变化。
人工智能研究者们已经开始尝试向机器 “喂养” 未标注的数据与部分标注数据,亦即 “半监督学习”,而不依赖于人工标注的自监督学习与数据标注,也在业界开始出现实践。
去年 6 月底,美国加州圣马特奥县的特斯拉办公室,多名特斯拉员工在一次会议中被告知,他们被裁员了。最终被裁员的 200 人中,大多数都是数据标注员。特斯拉目前正在开发的计算机 Dojo,就采用自监督学习技术,用于训练人工智能模型,对数据标注的需求正越来越低。

| 非洲的数据标注员
腾讯、阿里、字节跳动等一众大厂,也都在研发自监督学习的算法,甚至有些数据标注公司也都已经有 60% 内容来自于机器的自动化标注。
李杰听过一个说法,数据标注员是 “人工智能的老师”,是他和同事们日复一日的拉框,教会了人工智能理解人类世界。
但他从没想过,当人工智能时代真正到来的那一天,取代他们的,恰恰会是自己曾经的学生。
(为保护隐私,文中人物均为化名)

责任编辑:郭建