
For the first time in history! "AI vs Humans" work capability assessment, the results are not so good for humans

巴克莱分析显示,顶尖 AI 模型已接近人类专家水平,Claude Opus 4.1 获得 47.6% 胜率领先。AI 在零售贸易等领域已超越人类,在软件开发等职业表现优异。更令人震惊的是,AI 能力在 15 个月内提升 3 倍,呈线性增长趋势。预测未来 12-24 个月内 AI 将在大多数工作任务上全面超越人类专家。
OpenAI 最新发布的 GDPval-v0 评测工具首次量化了 AI 在执行具有经济价值工作任务方面的能力,结果显示 AI 正迅速追赶甚至逼近人类专业人员水平。巴克莱表示,最先进的 AI 模型已在诸多职业任务中达到与人类专家相当的能力,并且这种能力提升速度正在加快。
据见闻此前文章写道,OpenAI 最新发布了一款名为 GDPval-v0 的全新评估工具,涵盖美国 GDP 占比较大的九个商业领域中 44 个职业的约 1300 项具体工作任务,从法律文书到工程蓝图再到护理计划等真实工作交付成果。
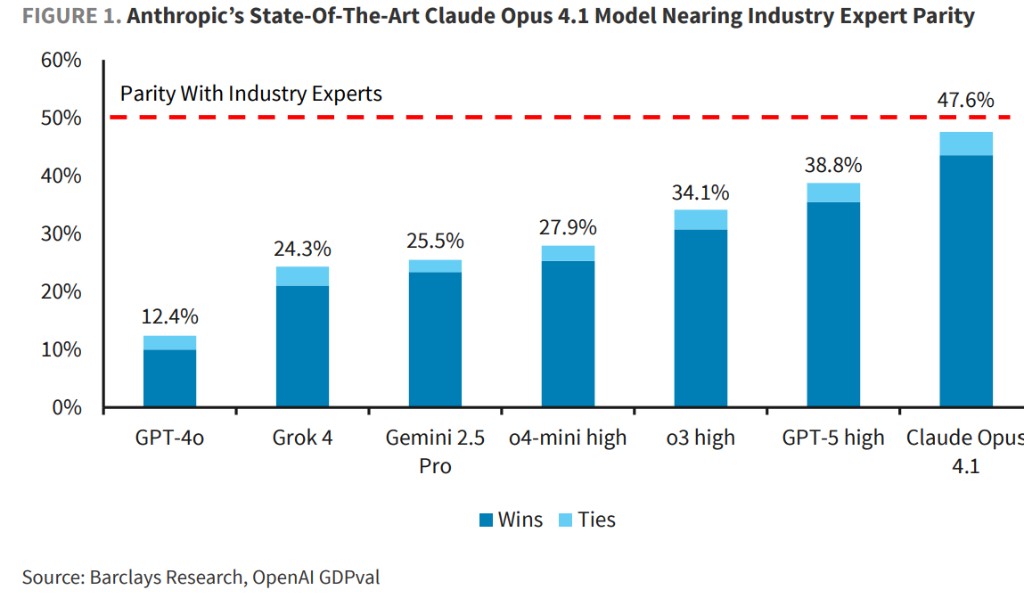
结果显示,当前最顶尖的 AI 模型在执行许多职业任务时,其能力已与人类专业人士相当,并且这种能力的提升速度正在加快。10 月 5 日,据硬 AI 消息,巴克莱在最新研究报告中称,Anthropic 的 Claude Opus 4.1 在与人类专家对比中取得 47.6% 的"胜利或平局"率,位居榜首。
巴克莱分析师认为,AI 模型的"胜率"在过去 15 个月中线性提升约 4 倍,预计在未来 12-24 个月内 AI 将在大多数工作相关任务上超越人类。分析认为,这一突破为评估 AI 投资回报率提供了关键数据支撑。
评测标准创新突破:模拟真实工作复杂性
据巴克莱研究报告,GDPval 基准测试的核心创新在于其真实性和复杂性。
该评测由平均拥有超过 14 年行业经验的资深专业人士设计,涵盖科技服务、金融保险、医疗保健、信息业、制造业等行业的 1230 个专业任务。
与传统基准测试不同,GDPval 的任务并非简单文本问答,而是包含参考文件和上下文的复杂场景,要求 AI 交付多样化成果,包括文档、幻灯片、图表和电子表格等。巴克莱指出,这种设计更贴近现实工作环境的复杂性。
评测采用盲测方式,由行业专家对 AI 和人类生成的工作成果进行排名,从难度、代表性、完成时间和整体质量等维度进行综合评估。
AI 性能接近人类专家水平
巴克莱分析显示,当前最先进的 AI 模型在多个领域已接近或达到人类专家水平。Claude Opus 4.1 以 47.6% 的胜率领先,GPT-5-high 紧随其后,达到 38.8%,o3 high 为 34.1%。
从行业维度看,AI 在零售贸易 (56% 胜率)、批发贸易 (53%) 和政府部门 (52%) 的表现超过人类专家,但在信息技术行业表现相对较弱 (39%)。
职业层面上,AI 在柜台和租赁文员 (80%)、运输接收和库存文员 (76%) 以及软件开发人员 (70%) 任务中表现最佳,而在工业工程师 (17%) 和影视编辑 (17%) 任务中表现较差。
各模型表现出不同特点:Claude Opus 4.1 在美学表现 (格式和布局) 方面表现出色,GPT-5 在遵循指令和执行准确计算方面最为精准。
能力提升速度惊人
巴克莱报告特别强调了 AI 能力提升的速度。
研报称,OpenAI 模型在 GDPval 测试中的表现在 15 个月内提升了 3 倍以上,这种线性增长趋势表明 AI 很可能在短期内全面超越人类专家。
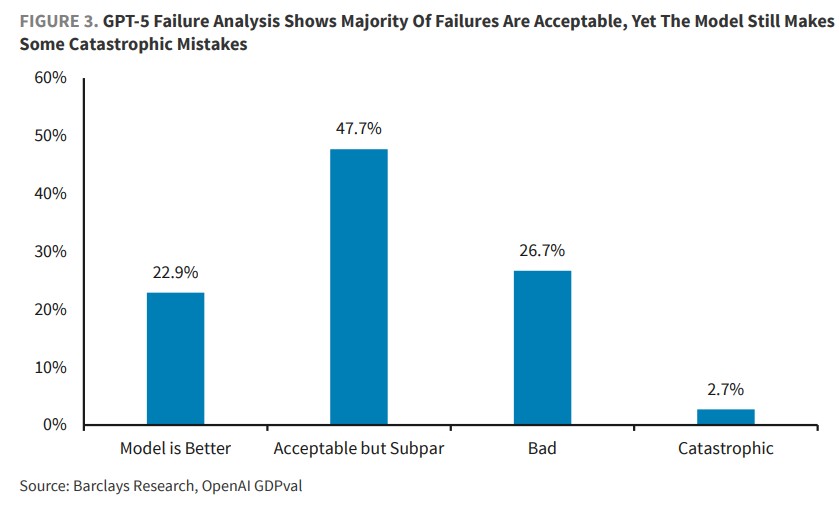
对 GPT-5 的失误分析显示,尽管该模型仍会犯一些灾难性错误 (2.7%),但 47.7% 的失误被归类为"可接受但不佳",22.9% 的情况下模型表现甚至优于人类。
巴克莱分析师认为,AI 模型的原始智能,特别是 GPT-5,已达到超越人类专家的水平。通过更多后期训练 (微调、强化学习),AI 全面超越行业专家的时代已为时不远。
