
Baidu Qianfan-VL is open source, and the purely domestically developed Kunlun chip achieves world-class performance

百度开源了全新的视觉理解模型 Qianfan-VL,包含 3B、8B 和 70B 三个版本,均在自研的昆仑芯 P800 上训练。Qianfan-VL 是一种多模态大模型,具备 OCR 和教育场景深度优化能力,能识别各种文字和复杂公式。在科学问答测试中,70B 版本获得 98.76 分,在中文多模态基准测试中得分 80.98,显示出其在中文图文理解上的优势。
百度把他们全新的视觉理解模型 Qianfan-VL 直接开源了。

Qianfan-VL 系列一共有三个版本,3B、8B 和 70B,参数量从小到大,分别对应不同的应用场景。
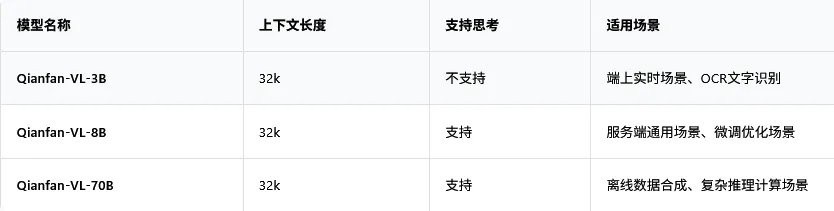
模型从头到尾,都是在百度自己家的芯片昆仑芯 P800 上训练出来的。
模型的性能和应用
Qianfan-VL 是一个多模态大模型,就是那种既能看懂图片又能理解文字的 AI。一张复杂的图表,它能分析出里面的数据和趋势。
它最核心的两个本领是 OCR(光学字符识别)和教育场景的深度优化。
你拍一张身份证,系统自动把你的姓名、证件号填好,这就是 OCR。Qianfan-VL 把这项能力做到了全场景覆盖,不管是印刷体、手写字,还是藏在街边招牌、商品包装袋上的艺术字,甚至是数学卷子上的复杂公式,它都能识别。发票、单据里的信息也能自动抽出来,变成结构化的数据。
而在教育场景,特别是 K12(从幼儿园到高三)阶段,它的目标就是成为一个超级学霸。拍照解题、几何推理、函数分析,这些都是它的强项。
Qianfan-VL 和国际上几个主流的多模态模型跑分对比。
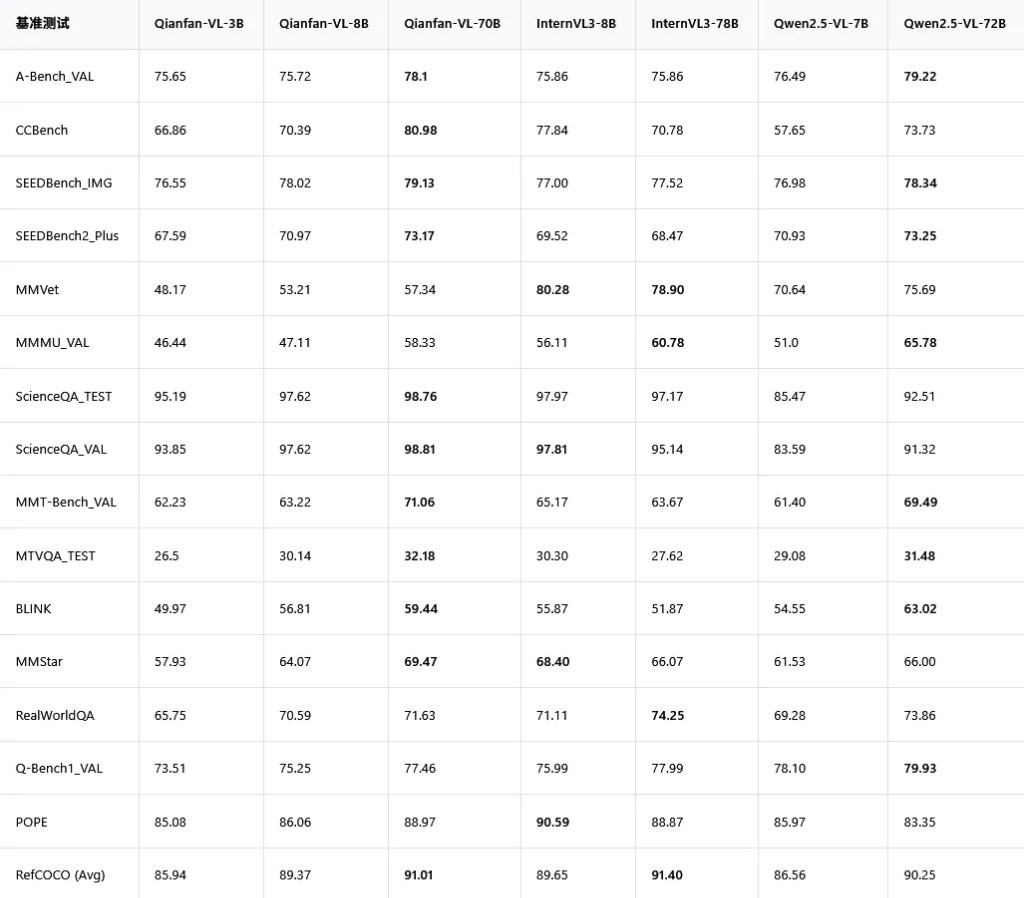
在科学问答测试 ScienceQA 里,70B 版本的 Qianfan-VL 拿到了接近满分的 98.76,把一众对手甩在身后。
尤其是在中文多模态基准测试 CCBench 中,Qianfan-VL-70B 拿到了 80.98 分,而同级别的对手只有 70 分出头。这说明它在理解中文语境下的图文内容时,优势非常明显。
在数学解题相关的几项测试,比如 Mathvista-mini,Math Vision 和 Math Verse 里,Qianfan-VL-70B 几乎是碾压式的领先。
纯血国产芯片训练
支撑 Qianfan-VL 模型训练的,是百度自研的昆仑芯 P800 芯片。
2025 年 4 月,百度点亮了国内首个全自研的 3 万卡昆仑芯 P800 集群。Qianfan-VL 的所有训练任务,都是在一个超过 5000 张昆仑芯 P800 卡的集群上完成的。
昆仑芯 P800 是个什么水平?
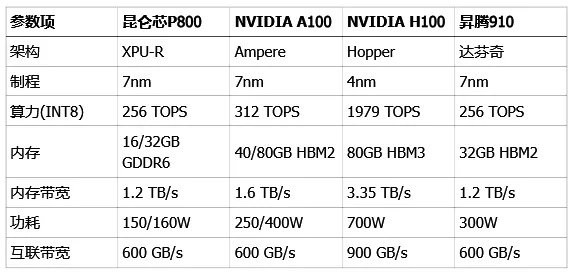
从纸面参数看,昆仑芯 P800 有一个非常突出的优点,就是功耗控制得极好,150W 到 160W 的功耗,远低于竞争对手。这意味着在组建大规模集群时,能耗和散热成本会更有优势。
昆仑芯 P800 真正的杀手锏在于它的架构设计。
P800 的 XPU-R 架构,从硬件上就把计算单元和通信单元分开了。这就好比把单行道改成了双向八车道,旁边还修了条专门给行人走的人行道。计算和通信各走各的路,互不干扰,可以同时进行。
百度把这个技术叫做 “通算融合”。通过精巧的调度,可以让数据传输的等待时间,完全被计算过程所掩盖。比如,在计算第一块数据的时候,第二块数据已经在传输的路上了,等第一块算完,第二块正好无缝衔接。这样一来,芯片的利用率被大大提高了。
基于这种能力,百度还推出了 “昆仑芯超节点” 方案,能把 64 张昆仑芯 P800 塞进一个机柜里。卡与卡之间的数据交换从速度较慢的 “机间通信” 变成了速度飞快的 “机内通信”,带宽直接提升 8 倍,单机训练性能提升 10 倍。
模型是这么炼成的
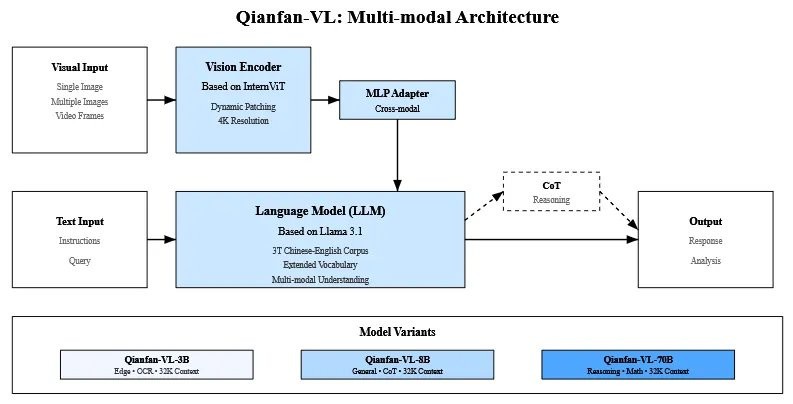
它的底层架构融合了业界的优秀成果。语言模型部分,小参数的 3B 版本基于 Qwen2.5,而主力 8B 和 70B 版本则基于 Llama 3.1。视觉编码器用了 InternViT,最高能处理 4K 分辨率的超高清图像。
精髓在于它的训练方法,百度设计了一套创新的 “四阶段训练管线”,像一个精密的四步升级程序。
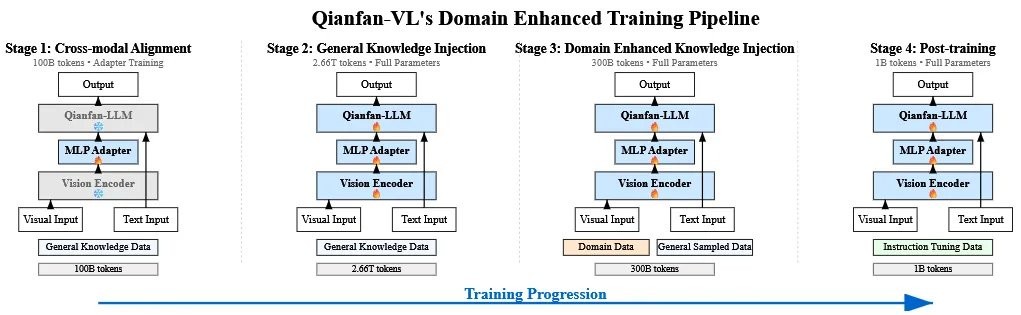
“跨模态对齐”。这个阶段的目标很简单,就是先让模型的语言部分和视觉部分认识一下,建立最基础的连接。训练的时候,只更新它俩之间的连接件(一个叫 MLP Adapter 的东西),语言和视觉模块本身都先冻结,避免互相影响。
“通用知识注入”。这个阶段开始给模型疯狂 “喂” 数据,总共投喂了 2.66T tokens 的通用知识数据。同时,模型的全部参数都放开进行训练。这个阶段的目标是为模型打下坚实的通识基础,让它成为一个见多识广的 “通才”。
“领域增强知识注入”。在成为 “通才” 之后,就要开始培养它的 “专长” 了。百度精选了大量高质量的 OCR、文档理解、数学解题等领域的数据,对模型进行专项强化训练。为了防止模型在学习专业知识时忘记了通用知识(这个现象在 AI 训练中被称为 “灾难性遗忘”),训练时还会掺入一部分通用数据。
“后训练”。经过前三个阶段,模型已经能力很强了,但可能还不太 “听话”。这个阶段就是通过大量的指令微调数据,教模型如何更好地理解和遵循人类的指令,让它变得更像一个得力的助手。
第三阶段使用的专业数据,是百度通过一套高精度数据合成管线自己 “造” 出来的。
目前,Qianfan-VL 的全系列模型已经在 GitHub 和 Hugging Face 等平台全面开源,企业和开发者可以自由下载使用。
百度智能云的千帆平台也提供了在线体验和部署服务。
GitHub:
https://github.com/baidubce/Qianfan-VL
Hugging Face:
https://huggingface.co/baidu/Qianfan-VL-70B
https://huggingface.co/baidu/Qianfan-VL-8B
https://huggingface.co/baidu/Qianfan-VL-3B
ModelScope:
https://modelscope.cn/organization/baidu-qianfan
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。
