
A new king of large models is born! Claude 3 surpasses GPT4 for the first time

Claude 3 超大杯 Opus 登顶榜首,大杯 Sonnet 和小杯 Haiku 分别获得第四和第六的好成绩,Haiku 水平已达到 GPT-4 级别。
作者:卜淑情
来源:硬 AI
一觉醒来,大模型世界迎来了 “新王登基”!
当地时间周三,聊天机器人竞技场 Chatbot Arena 更新对战排行榜,Claude 3 反超 GPT-4,一举摘得 “最强王者” 桂冠。
这次登顶榜首的是 Claude 3 系列的超大杯 Opus,它以 2 分 Elo 的微弱优势,险胜 GPT-4-1106-preview 模型,GPT-4-0125-preview 位列第三。
而且,不仅仅是超大杯 Opus,Claude 3 家族其他两个成员大杯 Sonnet 和小杯 Haiku 都杀进了 TOP10,分别获得了第四和第六的好成绩。
小杯 Haiku 达到 GPT-4 级别
尤其是小杯 Haiku,被官方单独拉出来表扬。
“Haiku 给所有人留下了深刻的印象,根据我们的用户偏好,Claude 3 Haiku 已经达到了 GPT-4 级别!” 运行 Chatbot Arena 的 LMSYS 平台发帖大赞,“它的速度、功能和上下文长度目前在市场上是独一份的。”

更难等可贵的是,Haiku 参数规模远远小于 Opus 以及任何的 GPT-4 模型,而且它的价格是 Opus 的 1/60,响应速度却是它的 10 倍。
GPT-4 自去年 5 月被纳入 Chatbot Arena 榜单以来一直牢牢霸占榜首,但现在,Claude 3 凭借其出色表现,尤其是其在高级任务处理上的能力,成功颠覆了这一格局。
“这是史上第一次,面向高级任务的第一模型 Opus 和面向成本效率的 Haiku 均出自非 OpenAI 的供应商,” 独立 AI 研究员 Simon Willison 在接受媒体采访时表示,“这非常让人欣慰——在这个领域,顶尖供应商的多样性对大家都有好处。”
“向新国王下跪!”
吃瓜网友也纷纷对 Claude 3 竖起大拇指。
“印象深刻,Very nice!”

还有人建议苹果将 Claude 设置为默认 AI 工具。

更有人直呼:“旧王已死。安息吧,GPT-4。”

“向新国王下跪!”


相比之下,网友对 GPT-4 的感情更加复杂。
“GPT-4 变得非常蹩脚。”

最近几个月,有关 GPT-4 变懒的话题在网上闹得沸沸洋洋。
据称,GPT 在高峰时段使用时,响应会变得非常缓慢且敷衍,甚至还会拒绝回应,单方面中断对话。
比如,它在进行编程工作时会习惯性地跳过部分代码,还出现了让人类自己写代码的名场面。

评分准确吗?
在一阵赞扬 Claude 3 的声音中,也夹杂着质疑的声音。

那么,Chatbot Arena 究竟是如何给这些大模型打分的?
Chatbot Arena 由伯克利大学主导团队的 LMSYS 开发。平台采用匿名、随机的方式让不同的大模型 “打擂台”,并让人类用户担任裁判,最后根据大模型所得的积分进行排名。
具体来说,系统每次会随机选择两个不同的大模型和用户匿名聊天,让用户决定哪款大模型的表现更好一些,系统会根据用户的选择对大模型进行打分,然后将分数汇总整理形成最终的积分,最后以排行榜的形式呈现。
自推出以来,已有超过 40 万名用户成为 Chatbot Arena 的裁判。新一轮排名又吸引了 7 万名用户加入。
在本次激烈的 “擂台赛” 中,Claude 3 通过成千上万次的对战,在 GPT-4、Gemini 等一众强劲对手中杀出重围,成为新的大模型之王。
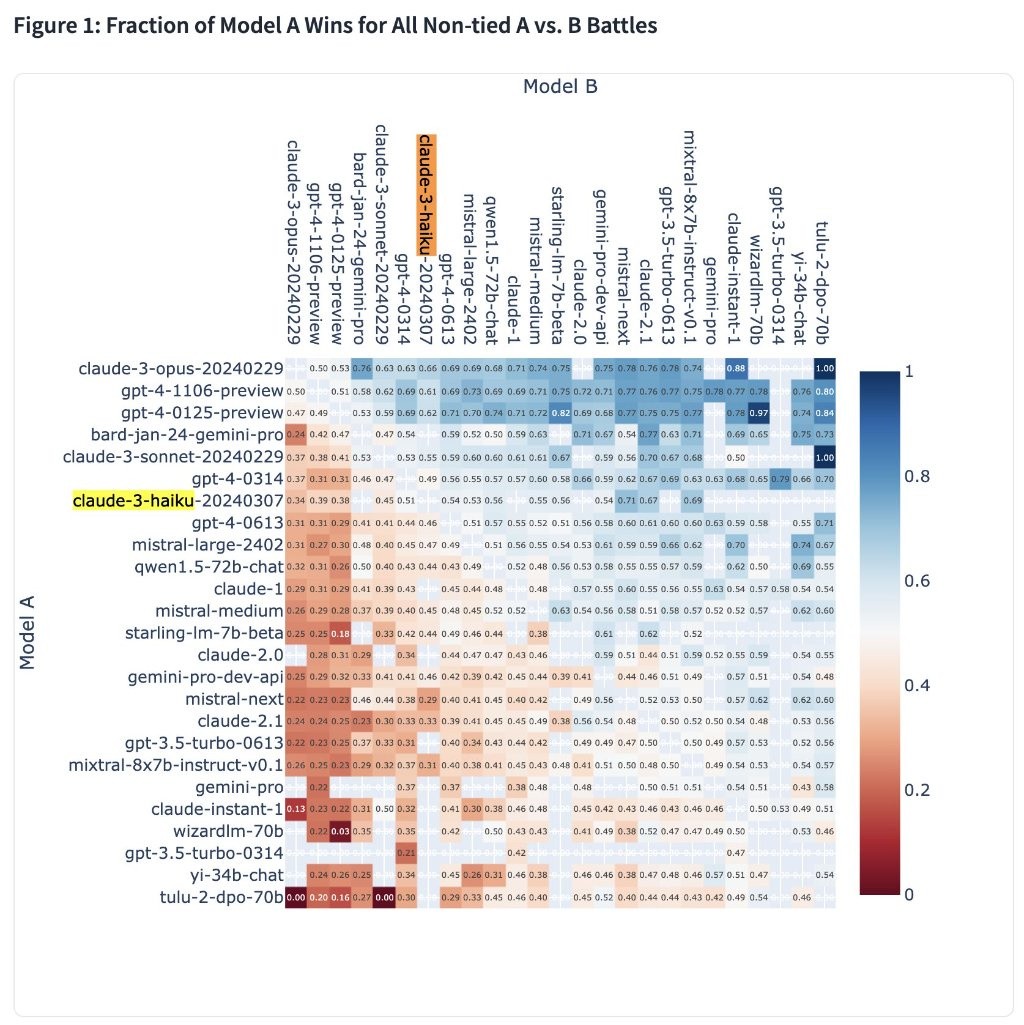
值得一提的是,在评价一个大模型的好坏时,用户的 “感觉” 也就是体验感至关重要。
“所谓的参数标准无法真正评价大模型的价值,” AI 软件开发者 Anton Bacaj 此前发贴说,“我刚和 Claude 3 Opus 进行了一场长时间的编码会话,真的是远超 GPT-4。”
Claude 3 的进化可能会令 OpenAI 感到一丝不安,一些用户已经开始在工作中 “叛变”,放弃 ChatGPT,转而使用 Claude 3。
“自从有了 Claude 3 Opus,我再也没有用过 ChatGPT。”
软件开发者 Pietro Schirano 在 X 平台写道:“老实说,Claude 3 > GPT-4 最令人震惊的事情之一,就是切换太容易了。”
但也有人指出,Chatbot Arena 并没有考虑到添加工具后的表现,这恰恰是 GPT-4 的强项。
另外,Claude 3 Opus 和 GPT-4 之间的分数非常接近,而且 GPT-4 已经问世一年了,预计今年某个时候会出现更强大的 GPT-4.5 或 GPT-5。


毋庸置疑,到那时这两大模型之间的 PK 将会更加激烈。
