
申万宏源:KIMI 确认爆款!国内语言大模型正式达到 GPT-4 水平

申万宏源证券表示,月之暗面的 KIMI AI 产品在大模型长文本能力上取得突破,达到了 GPT-4 水平。KIMI 能够精准定位办公人群,适用于高效阅读、专业文件解读、资料查询和整理等方面。KIMI 的上下文能力已达到 200 万字,支持全文总结和生成、联网搜索以及数据处理等多种实用场景。KIMI 的用户活跃度也在持续提升。
核心观点
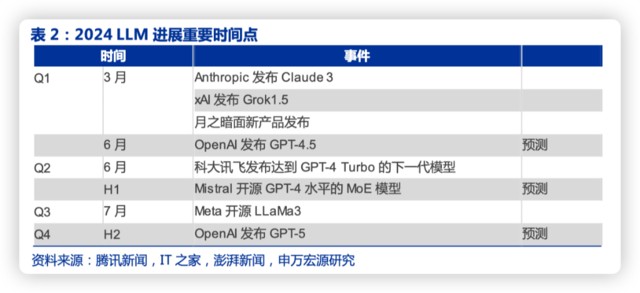
1)市场可能认为海外大模型迭代放缓,但我们认为 2024 年模型能力仍然快速迭代。包括 OpenAI 以外的其他模型能力追赶、Llama3 等开源大模型发布、下半年 OpenAI 的新模型迭代等;
2)市场可能认为国产大模型能力与海外差距极大,无法支撑任何应用,我们认为 kimi 等表明国产文字大模型能力已经达到 GPT4 水平,期待后续推理、数学、多模态等能力的迭代。
3 月 18 日,月之暗面宣布其 AI 产品 kimi,在大模型长上下文窗口技术上取得新的突破,Kimi 智能助手已支持 200 万字超长无损上下文,并于即日起开启产品内测。Kimichat 是月之暗面推出的对话助手工具,于 2023 年 10 月 10 日发布,发布之初即定位长文本。
支持输入 20 万汉字,是目前国产大模型中支持的最长上下文输入长度,2024 年 2 月,kimi 迭代了网站、多问题搜索能力,可用性继续提升。
3 月,上下文能力达到 200 万字。
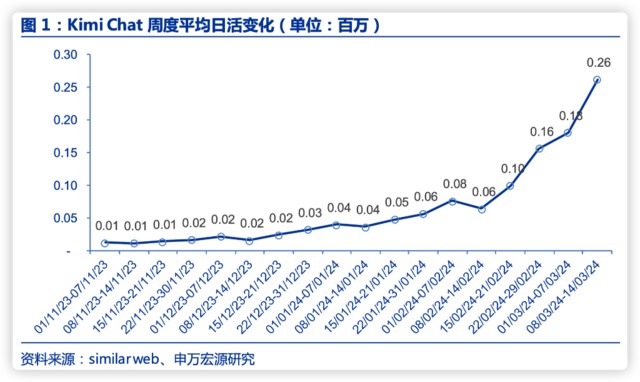
多次迭代后伴随着 Kimi 用户活跃度提升,2 月平均日活同比上升 101.9%,3 月前二周继续攀升。
更长的上下文能力意味着更多的实用场景。1)全文总结和生成:通过提问和文件上传等功能,能够迅速对众多文献和报告进行摘要提炼;2)联网搜索:能够搜索实时信息,迅速整合并给出详尽回答,同时提供信息来源,确保对话的丰富性和准确性;3)数据处理:把繁杂的数据整理成表格,以助于数据分析。除此以外 Kimi 还支持编写代码、用户交互、翻译等功能。
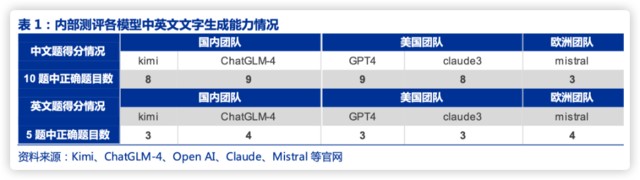
根据我们内部测评,国产大模型 Kimi 文字能力全面达到 GPT-4 水平。Kimi 中英文生成能力已经接近 GPT-4 水平,尽管逻辑推理能力仍有差距,且主打文字生成、目前无多模态能力;Cluade3 中英文生成、理解、推理,多模态图片理解能力均与 GPT-4 接近,效果好于 Gemini,且实际使用中生成速度快于 GPT-4 和 Gemini。
我们认为其在长文本单点能力上实现突破,精准定位办公人群。Kimi 支持 200 万汉字的长文本输入,对比来看,GPT-4Turbo-128k 的能力是约 10 万汉字,Claude3200k 上下文是约 16 万汉字。因此,Kimi 更适用于高效阅读、专业文件解读、资料查询、资料整理总结等方面。
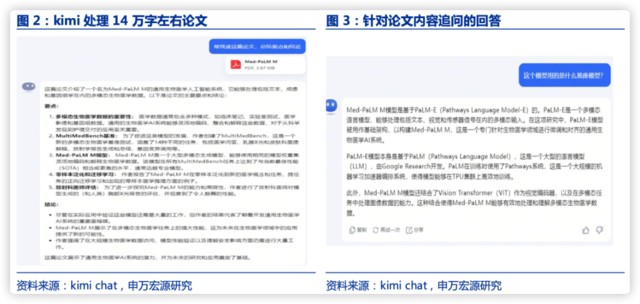
1)专业论文要点归纳总结任务的表现和 GPT4 大致相同,响应迅速,约 10 秒可以读完论文并给出回答。回答内容简要,并能够根据文档回答追问。
专业论文要点归纳总结任务的表现和 GPT4 大致相同,响应迅速,约 10 秒可以读完论文并给出回答。回答内容简要,能够根据文档精准回复追问,体现了模型较好的逻辑推理能力。
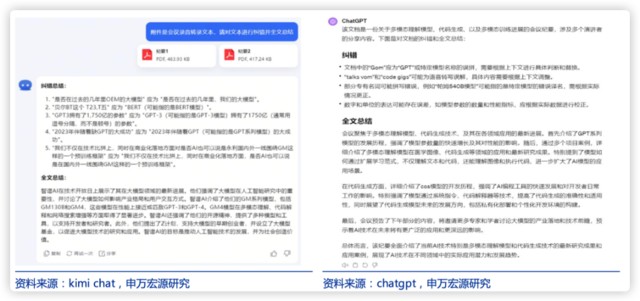
2)资料整理总结方面 kimi 在会议纪要总结能力上具有优势,选取一场会议的录音转录文本(分成两份 pdf)给到模型进行文本纠错和全文总结,kimi 的纠错能力和总结能力强于 GPT4,例如 kimi 能根据上下文将 “贝尔 BT 这个 T23,T 五” 这个乱码纠正为 “BERT”,并告知可能指 BERT 模型,其全文总结结果也比 GPT4 结果更具可用性。
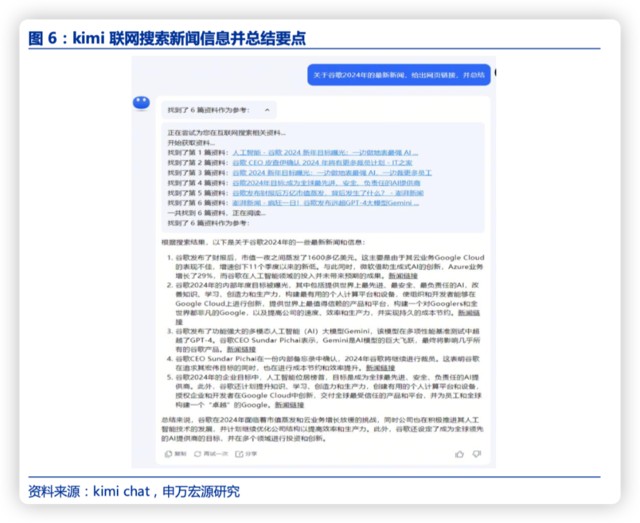
3)能够针对提问自动联网搜索总结回答,答案提供信息来源,更具可靠性。例如下图问 kimi 关于谷歌 2024 的最新新闻,基本涵盖了所有要点新闻,总结也到位。
总体来说,我们认为 kimi 的优势在语言理解、长文本处理、逻辑推理能力上,数学解题和多模态能力暂缺或稍弱。其长文本处理能力让论文总结、会议纪要变得更具可用性,加上联网搜索功能,对于需要查阅大量信息和处理会议纪要的办公人群有极大助力,未来办公类 AI 应用或将受益。
Kimi 成功启示:我们认为团队成员能力、资金储备、时间可能是 Kimi 目前较为成功的原因。
1)月之暗面(Moonshot)由清华大学交叉信息学院杨植麟教授领衔,团队成员包括来自 Google、Meta、Amazon 等国际科技巨头的人才,在 Gemini、盘古 NLP、悟道等多个大模型研发中有参与;
2)公司成立后获红杉中国、真格基金等机构投资,最新一轮融资超 10 亿美元,投资方包括阿里、红杉中国、小红书、美团等,估值达 25 亿美金;
3)月之暗面成立于 2023 年 3 月,此时 chatgpt 的全面成功,使得业界大模型已基本确认 Decoder-only+VQA 的技术路线,有效避免了此前由于技术路线分歧造成的开发资源浪费。
截至目前,国内大模型的文字生成能力已经整体接近 GPT-4Turbo。1 月 30 日,上 1 海人工智能实验室发布了大模型开源开放评测体系司南(OpenCompass2.0),结果显示,不少国内厂商近期新发布的模型在多个能力维度上正在快速缩小与 GPT-4Turbo 的差距,包括智谱清言 GLM-4、阿里巴巴 Qwen-Max、百度文心一言 4.0 等。
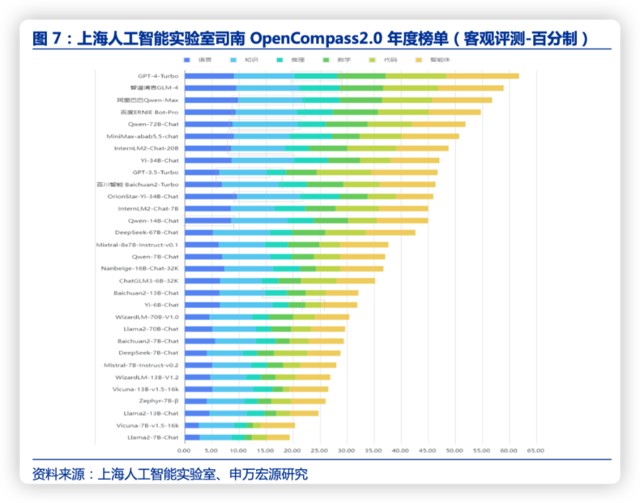
但同时根据评测,复杂推理相关能力是大模型普遍面临的难题,国内大模型相比于 GPT-4 还存在差距。评测显示,推理、数学、代码、智能体是国内大模型的短板。GPT-4Turbo 在涉及复杂推理的场景虽然亦有提升空间,但已明显领先于国内的商业模型和开源模型。这是大模型在金融、工业等要求可靠的场景落地需要的关键能力。
整体来看:
1)市场可能认为海外大模型迭代放缓,但我们认为 2024 年模型能力仍然快速迭代。包括 OpenAI 以外的其他模型能力追赶、Llama3 等开源大模型发布、下半年 OpenAI 的新模型迭代等;
2)市场可能认为国产大模型能力与海外差距极大,无法支撑任何应用,我们认为 kimi 等表明国产文字大模型能力已经达到 GPT4 水平,期待后续推理、数学、多模态等能力的迭代。
本文作者:证券分析师 洪依真 A0230519060003 刘洋 A0230513050006 林起贤 A0230519060002,来源:申万宏源证券
