







黄仁勋在 COMPUTEX 大会上说了什么?这里是最全的亮点
英伟达 CEO 黄仁勋在 COMPUTEX 大会上抛出多个重磅信息,包括新的机器人设计、游戏功能、广告服务和网络技术。其中最为引人瞩目的是,搭载 256 颗 GH200 Grace Hopper 超级芯片的新型 DGX GH200 人工智能超级计算机,堪称 “算力杀器”。谷歌云、Meta 和微软将是第一批获得 DGX GH200 访问权限的公司,并将对其功能进行研究。
5 月 29 日周一,英伟达 CEO 黄仁勋在 COMPUTEX 大会上抛出多个重磅信息,包括新的机器人设计、游戏功能、广告服务和网络技术。其中最为引人瞩目的是,搭载 256 颗 GH200 Grace Hopper 超级芯片的新型 DGX GH200 人工智能超级计算机,堪称 “算力杀器”。
谷歌云、Meta 和微软是首批预计将获得 DGX GH200 访问权的客户,以探索其在生成型 AI 工作负载方面的能力。值得注意的是,算力的突破,将使得 AI 应用再次获得巨大提升,AI 赛道有望向下一个节点迈进。在周一的演讲中,黄仁勋认为科技行业的传统架构的改进速度已不足以跟上复杂的计算任务。 为了充分发挥 AI 的潜力,客户越来越多地转向加速计算和英伟达制造的 GPU。
黄仁勋说:
我们已到达生成式 AI 引爆点。从此,全世界的每个角落,都会有算力需求。
有评论认为,一连串的发布凸显了英伟达正在从一家 GPU 制造商转变为一家处于 AI 热潮中心的公司。

上周,由于对处理 AI 任务的数据中心芯片的强烈需求,英伟达大幅提高了对本季度的业绩指引,比分析师的估计高出近 40 亿美元。业绩指引的提高使该股创下历史新高,并使英伟达的估值接近 1 万亿美元,这还是芯片业中首次有公司市值达到这一高度。
在周一的会议上,黄仁勋发布的主要内容包括:
- 英伟达面向游戏玩家的 GForce RTX 4080 Ti GPU 现已全面投产,并已经开始量产。
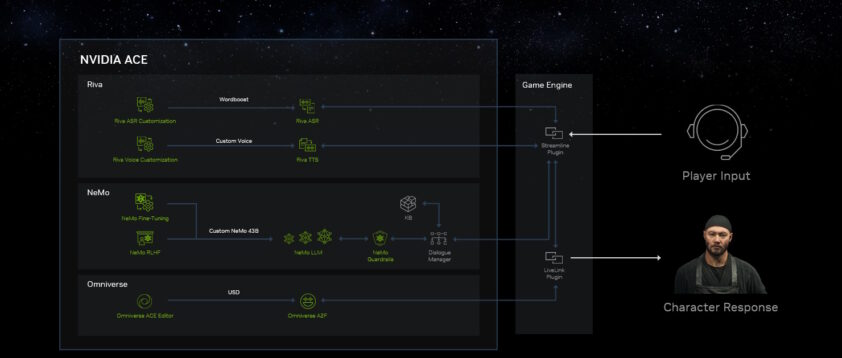
- 黄仁勋宣布推出适用于游戏的英伟达 Avatar Cloud Engine(ACE),这是一种可定制的 AI 模型代工服务,为游戏开发人员提供预训练模型。它将通过 AI 支持的语言交互赋予非玩家角色更多个性。
- 英伟达 Cuda 计算模型现在服务于 400 万开发者和超过 3000 个应用程序。Cuda 的下载量达到了 4000 万次,其中仅去年一年就达到了 2500 万次。
- GPU 服务器 HGX H100 的全面量产已经开始,他补充说,这是世界上第一台装有变压器引擎的计算机。
- 黄仁勋将英伟达 2019 年以 69 亿美元收购超级计算机芯片制造商 Mellanox 称为其有史以来做出的 “最伟大的战略决策之一”。
- 下一代 Hopper GPU 的生产将于 2024 年 8 月开始,也就是第一代开始生产两年后。
- 英伟达的 GH200 Grace Hopper 现已全面投产。超级芯片提升了 4 PetaFIOPS TE、72 个通过芯片到芯片链路连接的 Arm CPU、96GB HBM3 和 576 GPU 内存。黄仁勋将其描述为世界上第一个具有巨大内存的加速计算处理器:“这是一台计算机,而不是芯片。” 它专为高弹性数据中心应用而设计。
- 如果 Grace Hopper 的内存不够用,英伟达有解决方案——DGX GH200。 它是通过首先将 8 个 Grace Hoppers 与 3 个 NVLINK 交换机以 900GB 传输速度的 Pod 连接在一起,再将 32 个这样的组件连接在一起,再加上一层开关,连接总共 256 个 Grace Hopper 芯片。 由此产生的 ExaFLOPS Transformer Engine 具有 144 TB 的 GPU 内存,可用作巨型 GPU。黄仁勋说 Grace Hopper 速度非常快,可以在软件中运行 5G 堆栈。 谷歌云、Meta 和微软将是第一批获得 DGX GH200 访问权限的公司,并将对其功能进行研究。

- 英伟达和软银已建立合作伙伴关系,将 Grace Hopper 超级芯片引入软银在日本的新分布式数据中心。这些将能够在多租户通用服务器平台中托管生成式人工智能和无线应用程序,从而降低成本和能源。
- 软银和英伟达的合作伙伴关系将基于英伟达 MGX 参考架构,该架构目前正在与一些公司合作使用。它为系统制造商提供了一个模块化的参考架构,帮助他们构建 100 多个用于 AI、加速计算和全方位用途的服务器变体。合作的公司包括 ASRock Rack、Asus、Gigabyte、Pegatron、QCT 和 Supermicro。
- 黄仁勋发布了 Spectrum-X 加速网络平台,以提高基于以太网的云的速度。它包括 Spectrum 4 交换机,它有 128 个端口,每秒 400GB 和每秒 51.2TB 的传输速度。黄仁勋说,该交换机旨在实现新型以太网,并设计为端到端以进行自适应路由、隔离性能和进行结构内计算。它还包括 Bluefield 3 Smart Nic,它连接到 Spectrum 4 交换机以执行拥塞控制。

- 世界上最大的广告公司 WPP 已与英伟达 Nvidia 合作开发基于 Nvidia Omniverse 的内容引擎。 它将能够制作用于广告的照片和视频内容。
- 机器人平台英伟达 Isaac ARM 现在可供任何想要构建机器人的人使用,并且是全栈的,从芯片到传感器。Isaac ARM 从名为 Nova Orin 的芯片开始,是第一个机器人全参考堆栈,Huang 说。
在发布会上,黄仁勋还展示了生成式 AI 以文字形式输入然后以其他媒体输出内容的能力。他要求播放与清晨心情相配的音乐,而在另一篇文章中,他列出了一些歌词,然后使用 AI 将这个想法转化为一首活泼的流行歌曲:
现在每个人都是创作者。

值得注意的是,本次大会上,黄仁勋向传统 CPU 服务器集群发起 “挑战”。他直言,认为在人工智能和加速计算这一未来方向上,GPU 服务器有着更为强大的优势。
黄仁勋解释称,传统上电脑或服务器最重要的 CPU,这个市场主要参与者包括英特尔和 AMD。但随着需要大量计算能力的 AI 应用出现,GPU 将成为主角,英伟达主导了当前全球 AI GPU 市场。
黄仁勋在演讲上展示的范例,训练一个 LLM 大语言模型,将需要 960 个 CPU 组成的服务器集群,这将耗费大约 1000 万美元,并消耗 11 千兆瓦时的电力。相比之下,同样以 1000 万美元的成本去组建 GPU 服务器集群,将以仅 3.2 千兆瓦时的电力消耗,训练 44 个 LLM 大模型。
如果同样消耗 11 千兆瓦时的电量,那么 GPU 服务器集群能够实现 150 倍的加速,训练 150 个 LLM 大模型,且占地面积更小。而当用户仅仅想训练一个 LLM 大模型时,则只需要一个 40 万美元左右,消耗 0.13 千兆瓦时电力的 GPU 服务器即可。
换言之,相比 CPU 服务器,GPU 服务器能够以 4% 的成本和 1.2% 的电力消耗来训练一个 LLM,这将带来巨大的成本节省。
根据 Trend Force 的数据,2022 年搭载 GP GPU 的 AI 服务器年出货量占全部服务器的比重接近 1%,2023 年在 ChatGPT 等人工智能应用加持下,AI 服务器出货量有望同比增长 8%,2022~2026 年出货量 CAGR 有望达 10.8%,以 AI 服务器用 GPU,主要以公司 H100、A100、A800(主要出货中国)以及 AMD MI250、MI250X 系列为主,而英伟达与 AMD 的占比约 8:2。
基于 IDC 预测 2026 年全球服务器出货量 1877 万台、AI 服务器的占比逐年提升 1%,同时 AI 服务器中 GPU 的搭载数量逐年提升 0.5 个百分点、随着 GPU 产品迭代,GPU 单价逐年提升 2000 美元,国金证券基于上述基础预测,2026 年全球数据中心 GPU 市场规模有望达 224 亿美元。